
文/余亮
无论2016年科技圈热门的噱头有多少,对数据基础设施方面的耕耘仍然是决定实力的关键。阿里之类电商数据帝国自不待言,今日头条、一点资讯等在资讯数据领域的开拓更加值得注目。比起电商的物流数据,资讯算法驱动与用户数据分析是更加“触及灵魂”的事情。
1月15日,在头条主办的“珠海未来媒体峰会”上,技术出身的CEO张一鸣走到台前,向台下一众媒体人发表演讲:《我眼中的未来媒体》。他纵横媒体发展史、国内外现状,从古腾堡到贝索斯,从App Store到Instant Articles,看似雄辩地证明媒体人把内容输送到算法推荐平台是大势所趋。
一点资讯紧跟其后。1月20日,在其与凤凰博报联合举办“凤凰一点通”年度影响力自媒体盛典上,一点资讯宣布打通两家平台,资源共享。一点资讯副总裁吴晨光面对台下上百位自媒体人,也在极力渲染一点资讯的读者画像等算法技术。鹬蚌相争刚刚白热化,已有一只黄雀在身后——腾讯的同类产品“天天快报”已经低调运营了一段日子,不知道在憋什么大招。
人们应该记得,2014年多家传统媒体因版权问题对今日头条发起声势浩大的诉讼。2015年11月也有媒体发起对一点资讯的版权诉讼,但反响很小。再到如今,媒体人坐在台下为张一鸣鼓掌捧场。也许真是时势变化,技术的发展已经让内容生产者从惊恐到不得不适应。
头条不是百度,推荐引擎有别于搜索引擎。其实头条所自豪的算法推荐也不是这几年才出现,谷歌、百度都是前辈,为什么是头条让算法成了颇具神秘感的明星?
头条出名以来,一直有人吐槽推荐算法不准确、制造信息茧房,一些评论者宣称装了就卸载。我也有同感。不过就像帝吧远征之人力洪流带来的震撼,今日头条巨大的流量也促使我重新审视算法洪流。别忘了头条招聘启事上写着:“对用机器学习算法解决现实问题有强烈的渴望和坚定的信仰。”
尚显粗糙的算法,正在成长的生命
我先抛出对算法的总体观点,有三个层面:
首先,算法是一种类似金融资本的东西,是方法。就像财务投资者不必追求理解公司具体产品本身,只在乎能否增值。算法不管内容实质是什么,只管能否数字化、分类集合、反馈优化,是处理海量信息的方法。与资本一样,它能提升效率,也与个体有矛盾。
第二,张一鸣在演讲中说Facebook把技术支持变成了一项接近水、电、煤气这样公共服务的事情。再进一步,当算法深入生活的方方面面,积累的智能本身将成为基础设施。KK(凯文·凯利)在新书《必然》里说到,未来的人工智能网络(主要包含算法)将会成为“如同电力一样无处不在、暗藏不现的低水平持续存在”。比如办公室的桌椅和电脑都会识别你,记录你喜欢的姿势,在你一走进办公室就调整好姿态,打开你常用的软件、网站等等。
但对于资讯内容传播来说,这还不够。内容不是桌椅,桌椅只要伺候我们,内容却是装载了他人灵魂的存在,要和我们互动、砥砺。这就是第三层,算法要想触及灵魂,还得努力。
头条到底是什么?有人已经说了它不是新闻客户端,而是信息分发平台。仅此而已?
张一鸣演讲称:
“将对媒体在今日头条平台上的用户数据进行更详尽的统计分析。除了性别、终端、年龄、地域分布等用户属性基本分析外,还将提供用户的兴趣和情感倾向分析。通过这一功能媒体可以知晓受众喜欢哪些分类的文章、用户最喜欢文章里的哪些关键词、关注你的人还喜欢哪些内容等等。”
这话本意是针对微信,微信公众平台目前恰好只能提供受众的“性别、终端、年龄、地域分布”分析。兴趣和情感,这是算法更高的追求。
头条的销售人员在推销自家产品时,可以告诉一家汽车制造商:用户的阅读行为数据能够展现出哪个地方的人最喜欢你们的哪一款车,我们将把你们的广告推送给合适的读者。今日头条的同类产品“一点资讯”也在做同样的事情。创始人郑朝晖曾对内容总监吴晨光强调:“比阅读重要的是阅读者的行为。”
所以头条们在做什么?今日头条是伪装成新闻客户端的用户行为数据收集器和分析器!(这感觉就像有位美国政治学者说的,现代中国是一个伪装成民族国家的文明帝国。)每一篇新闻都应该被看作一道对用户的测试题,用户的每一次点击、评论都是一种回答,都被系统记录,和关键词、Dom标签、作者、阅读时间、网络环境(wifi还是4g?)等等一起构成多维数据矩阵,刻画出这个读者的特征。每道“测试题”都很粗糙,但是就像KK的“蜂巢思维”所言,海量资讯一起测试出的用户特征就比较准确。而且用户因为是在无意识中完成测试的,答案比较真实。这就是头条们的技术和商业模式核心所在。
读者难免会质疑,你倒是收集好数据了,可是给了我们什么?读者也不需要流量,要的是信息的准确和善解人意。
我们不妨把算法看作一个正在成长的生命。
普通读者这些年对算法推荐的直观感受并不佳:浏览了某个淘宝页面之后再去其他网站,页面也会浮现同类产品的广告,如果浏览的是情趣用品呢……在头条看新闻也很容易遇到这种情况——相似资讯不断涌来。(可参见虎嗅上这个批评:《我为什么看衰内容的个性化推荐?》)
粗解今日头条的算法
经常被头条员工拿出来说的简单算法是AB测试和双盲检验。
算法架构师曹欢欢和增长团队的张楠都公开讲解过,如何用AB测试来判定一个产品修改的效果。比如一个按钮是用红色好还是用蓝色好,那么就各向1%的用户发布两种颜色产品,哪个下载得好就推哪个。如果用在新闻上,就是同一条新闻由编辑给两种标题,测试哪个标题点击好。
双盲检验,是先让算法判断一个新闻的分类和推荐对象,然后让两个编辑分别检验,如果结果一样,就通过,不一样就请第三人判断并汇报程序员,重新调整算法。在我看,这背后是一个类似神经算法的“刺激-反应”模式——根据算法反应对错调整某个参数(权重),也是一种人工智能里常见的“半监督式学习”。这大概也是张一鸣口中人机结合、发挥人的智慧的证据之一。
不过在这个例子中,编辑的角色比较被动,像工厂流水线上的螺丝。
我注意到今日头条在拉勾网打出一个百万美元年薪的广告,招募算法架构师,要求擅长:贝叶斯学派相关算法,超大规模离散LR,深度神经网络,各种tree-based的算法等。其他算法工程师岗位要求大同小异。
这些在技术人士眼中并不特别,很多IT公司必备,多和概率统计学有关。比如贝叶斯算法,常用的邮件客户端上就有出现。
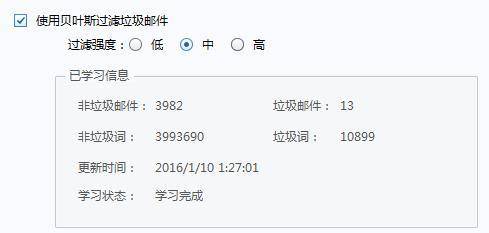
Foxmail截图
我想尽我所能简单介绍一下这位百万年薪工程师具备的算法知识,不从数学专业角度(专业角度我也不懂,否则我就去应聘了~),而是从用户角度思考“算法想要什么”。
以招聘启事中的tree-based算法为例。为了处理信息,算法的初始诉求往往是对海量信息做分类聚合。人类眼中的词汇在它眼里都是参数(维度),一千个不同词汇组成的一篇文章就是一千个维度组成的一个向量。然后机器在代数世界里衡量不同向量的相似度——简单向量距离分类法、贝叶斯算法、KNN(K最近邻居)算法、线性回归、逻辑回归……
维度太多,于是算法进化了,不再把每个词当作维度,而是把html代码里的节点标记(DOM)作为维度,这样就大大减少了维度个数。人类看见的标题、文字、图片,被代码放在不同的DOM节点里,比如head,比如body,比如TR、TD(表示表格的代码),构成树状结构。算法以这些节点为维度,用各种算法对比不同的文档异同——k means(硬聚类)算法,minimax(极小化极大算法)……再进一步,引入图论范畴的模式树,就有了更高级的tree-based算法。
下图是个常见的html dom展示,不需要看懂,只要了解机器眼中的文章是什么样子。
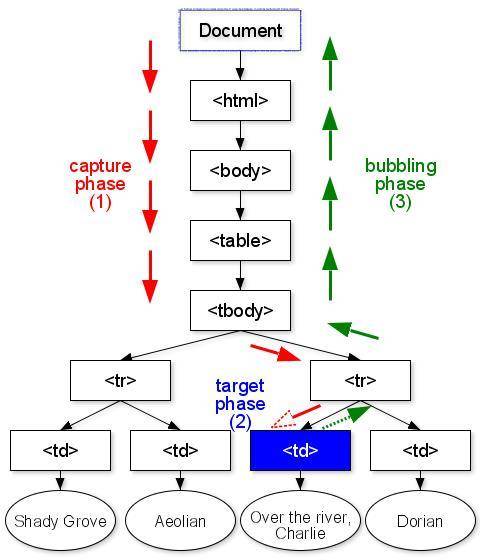

(机器眼中,各种标记最重要,然后通过各种公式来处理。图片来自爱范儿,公式来自酷勤网)
算法五花八门,我说的也不准,主要看气质——算法这个孩子不知道新闻说了什么,只知道哪些新闻是同类,哪些是热点(点的人多当然就是热点,机器可以通过一种“组合”算法来判断,可以参见南京大学新闻传播学院助理研究员、奥美数据科学实验室主任王成军的文章《“今日头条”怎么计算:“网络爬虫+相似矩阵”技术运作流程》)。文章标签、关键词等也起到作用。
算法的行为很有趣,好像在努力用各种办法躲避对内容灵魂本身的认知,只通过外表的形式特征去猜内容的相关度。
读者身上没有关键词,没有标签,算法如何把握?数学家们有办法,贝叶斯算法就是一种。
经典的贝叶斯问题在小学奥数里就有(美剧《生活大爆炸》里也出现过):假如分别有A、B两个口袋,口袋A里有7个红球和3个白球,口袋B里有1个红球和9个白球,现从这两个口袋里任意抽出了一个球,且是红球,问这个红球是来自口袋A的概率是多少?
让我们换一个更具新闻性的表达方式:假如已知韩国每5年发射一次卫星且每次爆炸失败率是60%,朝鲜每2年发射一次卫星且每次爆炸失败率是40%。现在从朝鲜半岛传来一声卫星发射失败爆炸的巨响,请问这枚火箭来自朝鲜的概率是多少?
根据贝叶斯公式【P(B|E) = P(B) × P(E|B) / P(E))】就可以推导出这个概率来,也就是逆向计算概率。
(图片来自“机器之心”网站)
恰好头条自己提供了一个范例:
2015年10月,在中国传媒大学新媒体研究院和今日头条联合举办的“洞见数据的力量——电视媒体高峰论坛”上,一位叫做安娜的女士说:
头条有个独特的算法能推算用户的年龄,即使你没在头条订阅。系统根据已确定年龄人群的动作、特点和兴趣做了一个模型,由协同原则判断读者是否符合这个模型,这时机器先预判是否为该年龄段的用户,同时机器再根据你的阅读动作最终确定年龄段。
这个独特的算法可能就是贝叶斯算法(当然也许不止一种算法,比如也可能存在专门用于挖掘不同数据集合间关联性的Apriori算法等)。我猜想算法架构师会预先根据心理学、社会学统计数据以及以往读者点击数据,构建一个用概率来描述的人格特征模型,比如男性模型的特征之一是在阅读新闻时点击军事新闻的概率是40%,而女性模型是4%。一旦一个读者点击了军事新闻,算法就开始逆推TA的性别,加上TA点击其他新闻的行为数据,综合计算,就能比较准确地判断TA的性别。综合IP地址(地理信息)、点击时间、评论参与、点赞行为这些明确的信息,就能区分出不同读者的取向、兴趣。
原理不难理解,但做起来考验智慧和耐心。
但是,算法并不像它自己吹嘘得那么神,它有很大的困境
困境1:它并不能区别风格,也无法产生风格
算法团队本身是较难产生风格的。头条、一点资讯和天天快报究竟有多少区别呢?
风格既人,风格即灵魂。鸡蛋个个不同但那不是风格,只是原始特征。风格是一种需要积极建构的气质,是生气灌注的行动。
传统媒体都是有风格的,没风格的不是死了,就是僵尸媒体。
下面这个微博截图体现了风格:
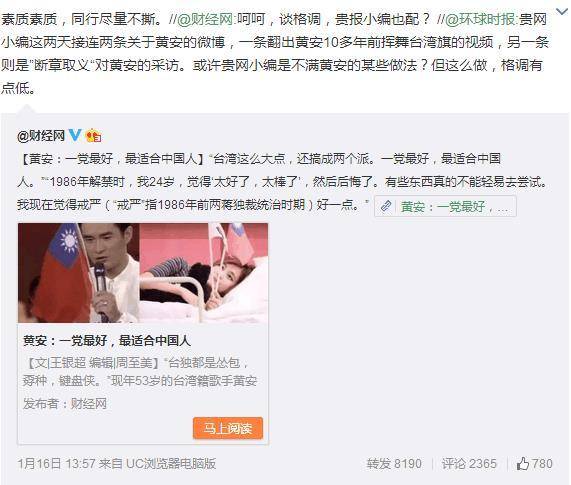
美国的纽约时报和赫芬顿邮报同一个“美国梦”,也具有显著不同的气质。有自己相信并追求的价值观,追求新闻事实时候有非如此不可的冲动,写作时有难平之意化为不休的诉歌,这才是风格。
风格是原创,是观点交锋,是议程设置,是话语创新。算法还没学会这些,因为设计算法的技术人可能还不太懂这些。
这还不只是差异化竞争问题,更重要的是产品的内在矛盾。头条们不止是平台,因为伪装不是白装的,新闻客户端的表象与算法机器的矛盾是无法摆脱的“原罪”。形式不是内容之外可有可无的事物,形式就是内容。头条们注定不可像没有首页推荐的微信公号平台一样,真的只做完全中立,没有一点情感和立场的平台。人们都认为你是资讯客户端,你就要做资讯媒体的事情,哪怕和算法的性格有矛盾。但矛盾不是缺陷,矛盾是推动自身进化的动力所在。
他们想有风格。
起步较晚的“一点资讯”在努力表现自己的风格,比如宣称自己是做兴趣搜索,有别于头条的算法推荐。吴晨光宣称一点资讯是“百度+头条”:
“正如一点资讯董事长刘爽所说,如果头条是造纸术和印刷术,那么一点资讯就是火药和指南针。这两个APP都以‘千人千面’为核心竞争力,因为确实像造纸术一样改变了传播。但一点比头条更近一步:所谓火药,是通过搜索唤醒了沉睡在APP里的信息,你可以通过搜索、订阅,两步完成你对任何你感兴趣内容的定制。至于指南针,我这样理解:因为一点后台有非常精准的用户画像,所以可以把最符合你兴趣的内容分发给你。用我们内部的一句话说:大事件作出共鸣,个性化要像蛔虫。”
可以看出来,作为后起者,一点资讯一方面不得不通过头条来定义自己,同时又必须有所区别,特别强调搜索。不过从用户直观感受来讲,这种区别是很难看出来的。头条一样有搜索功能,也会记录读者的搜索行为。可能,郑朝晖有雅虎的经历,在搜索上会有独到经验。
至于“指南针”,只是一个更生动的比喻。所描述的“用户画像”,可以猜想也是和贝叶斯算法之类大同小异的方法。
看拉勾网上“一点资讯”的招聘,唯一的算法师招聘广告要求:
“文本分类和语义理解,社交网络分析,网页搜索,推荐系统等领域的特定算法,理解自然语言处理、机器学习、网页搜索,推荐系统,用户数据分析和建模的基本概念和常用方法。”
应该说,所谓“特定算法”大家都类似。具体的公式和策略五花八门,但那只是鸡蛋的不同,最多在比拼谁的算法最state of the art。能区别风格的还是操作者的思想理念、媒体情怀和舆论场的洞察判断力。同样的算法,具体开发时候也要看悟性、灵性。谷歌与百度在用户看来,最直观的区别也还是理念和情怀的不同。
相比之下,吴晨光强调一点资讯在提高自媒体门槛的做法,这种筛选是由媒体人团队做到的,我认为更重要。
“最近两个月,一点资讯封掉了大概7000多个号。古玩、健康、财经等,都是重灾区。我们的竞争对手,在放宽入驻条件,但我们相反——高标准,并且实行严格的分级制度。从一级到六级,级别越高标志着你的内容越优质,这样你得到的展示量就越大。”
这是在用人的智力为算法提供可贵的参数。
头条大举招募媒体人入驻平台,并加大对自媒体平台的投入,这是有意识地抢占底盘,获得内容版权,也是无意识地要让自己更生动。
可是算法尚不能理解这种风格化的努力。
困境2:引导读者走进信息的茧房,沉沦于本我
我试着用社会心理学的语言来描述算法独尊主义带来的信息茧房问题。
算法和读者一起,沉沦于本我的漩涡。本我的欲望让你去点击了一条惊悚的社会新闻,但本我不是人性,对本我的自省和超越才是人性。反复涌来的社会新闻会让读者生厌。这个一直被人质疑的问题似乎没有得到透彻的说明和改善。
求证过员工自己对这个问题的看法,他们会告诉你不喜欢这样的信息就用手指划掉,系统就会减少此类信息推送。我在虎嗅上也看到类似的回答,如下图:

算法只计算异同关系,只机械地问你要还是不要,而没有计算诸如相对关系、主从关系等等复杂的关系。就像一个不太会恋爱的直男,听到对方说no的时候,并不善解对方真正的意思。
我同意虎嗅上这个读者的说法:

算法能否采用更好的策略,除了数学思维本身,还在于算法对人性的理解。非线性思维才能贴近人性——哪怕是庸常之辈,也会渴望有一只手能托起自己的头颅。假如用户多点击了几次惊悚社会新闻,算法可以继续推送同类资讯,但是一定要显出一种“我猜你其实也是个有高尚趣味的人”的姿态——可以于惊悚新闻信息流里突然插入一条洗眼资讯,可以是正能量,可以是对立面,可以是新闻分析。既然瀑布流里面可以插入广告,为什么不能插入和用户点击趣味相反的文章?
我不了解具体算法设计问题,也许需要更复杂的集合算法。每条资讯有自己对应的镜像,就像本我对应的超我,就像西斯武士对应的绝地武士。不甘做机器保姆的小编可以参与打造这样的集合,提升机器灵魂的同时提升自己,共同进化。彼此是对方的启蒙者,而不是做一个被动的仆人。也许会有偏差,会有博弈,但魅力就在这里。在《失控》看来,人机之间要有一定的对抗才能共同进化。也许算法在等待读者自己走出沉沦,但对抗就要求算法更弹性一点,更抢先一点,主动试探读者是否想要逆风而行。
用资讯测试读者,是把读者看作已完成的人格。而人性是永远在路上的未完成之物。人性和人类的创造物,需要彼此激发,螺旋上升。分类聚合算法只是把自己看作一个置身事外的观察者,正如科学试验里的观察者,以为自己不在事件之中。但这是不可能的,算法已然在参与人性的构建,只是采取了消极的方式——人以群分,每个人沉沦在自己的趣味里。后果是读者的极化,老死不相往来,像黑客帝国里的人茧。人茧衰弱的同时,系统的活性也在衰减。
极端分化的人群与极端分化的信息一样,缺少活性。而搜索引擎则没有那么主动地去极化人群。人在搜索时候主动性更强,我倒希望一点资讯是在利用搜索引擎收集读者的主动性方面有所建树,以此刺激算法。
我们可以用贝叶斯算法本身的问题来解释这个危险:
研究者John Horgan在《科学美国人》上发表了一篇文章《被追捧和被歪曲的贝叶斯理论,究竟有什么大不了?》(由“机器之心”网站提供中文翻译),讲述了贝叶斯算法自身的一个矛盾(具体论证过程此处免去,可参见上面的文章链接):
“贝叶斯理论没什么神奇的。归根结底,它就是在说,你的信念只和它的证据一样有效。如果你有好的证据,贝叶斯理论就能得到好结果。如果你的证据不足为信,贝叶斯理论也就没什么用。进入的是垃圾,出来的也是垃圾。”
对贝叶斯算法来说,初始确定的概率很重要,比如前面提到“40%的成年男性喜欢阅读军事新闻”,这个概率判断就是初始确定的概率,能通过社会统计获得比较接近现实的数字,一般也比较符合常识。但是对于很多事情,比如“上帝存在”,初始概率就难说了,有人会定为百分百,有人会定为零,于是最终结果不过反映了给出初始条件者自己的主观愿望。即便“40%的成年男性喜欢阅读军事新闻”,表达的也是现有的社会状况。最终的资讯推荐结果则反过来强化了这个初始概率——爱看军事的就更多地看到军事新闻。认为性别是后天建构的女性主义者恐怕就会讨厌这种刻板状况。
所以,目前的算法是不太懂得体贴各种人类需求的。未来它应该让不同的趣味,不同的人群相逢。
今日头条应该收购豆瓣而不是入股各种媒体
张一鸣演讲批评微信朋友圈信息推荐效率低,在某种程度上是对的。在朋友圈获得优质信息的效率取决于你的朋友质量,有精彩朋友才有精彩资讯,如果都是晒海滩的当然没意思。头条不受社交关系限制,对于缺乏丰富社交层次的人来说,获得信息效率高。可是缺少社交属性和社交关系的积累也是头条的软肋所在。
腾讯目前正在低调运行“天天快报”,与微信平台以及腾讯媒体开放平台分开,未来未必不会整合。那样就可以结合社交推荐和算法推荐,尤其可以利用朋友圈里各种专业人士、学者点赞推荐或阅读撰写资讯的行为(只要他们愿意公开)。帝国的反击迟早要来,头条们的算法武士应该尽早打造具有熵增能力的资讯关系,并发展一种把“兴趣”人格化的算法社交方式。
算法需要人,这话不止是说需要社交关系,而是策划者的想象力。我见过有人围绕豆瓣上的影片打分,手工收集打分者读书数据,非常有趣。比如给电影《胜利大阅兵》五星的人喜欢看什么书,给一星的人又看什么书。在这个基础上,如果加以聪明的算法,就可以激发出新型社交模式,不过这里不展开。
蓝媒汇报告称头条购买了不少媒体的股份,比如世界说、新榜、华尔街见闻等等。从算法的逻辑讲,我以为这不是最优的收购方向。在我看,与那些拥有社交数据的媒体比如微博合作才是对的。头条们应该收购豆瓣。不是说要做社交,而是要拥有社交数据并利用算法激活之。豆瓣之类集聚的人之想象力,为什么不能和机器算法互相滋养?
这些技术起家的公司已聘请资深媒体人加盟,头条请了林楚方,一点资讯请了吴晨光,都是媒体圈很有名气的主编级人物。不过媒体人目前的作用主要是公关,撬动自己掌握的丰富媒体资源,或者利用自己的表达能力替不善言辞的技术人表述产品。
我觉得,如果媒体灵魂和算法的结合暂时困难的话,何方先做智库?眼下官方对智库建设青睐有加,头条们的数据再加一点媒体眼光,就可提供很多技术落后智库无法提供的报告。
这需要人的想象力。比如最近帝吧远征脸书,举国震惊,也引发了很多评论。无论各方如何评价,这都是90后乃至00后网络新人的一次亮相。各方都不太了解他们,商业公司需要了解他们,政府机构也需要了解他们。众说纷纭,很多是从主观偏见出发。
想了解他们有很多办法,比如去采访他们,去贴吧收集材料做统计。但百度或者头条们显然可以有更快捷的智能办法,能够通过相关评论资讯的阅读和其他关联数据,来考察相关人群的特点,他们的地域分布,他们的收入状况,他们的兴趣爱好。
在9月大阅兵期间,范玮琪因为在微博晒娃遭到大量谩骂,有人批评骂人者是民粹,是买不起好产品的loser。但是学者邹振东通过大数据分析发现他们的组成和其他群体类似,iPhone使用率很高,颠覆了主观判断者的意见。并最终发现是微博的算法推荐导致范玮琪和读者的意外碰撞。
这些命题需要有人想到,才能动用算法去做。而人的因素不像算法可以总结成可复制的标准算法。
洞察并善用人的智慧,发挥人群的博弈,而不是让个人成为资讯喂食对象,才会让算法也变得更有灵气。今日头条、一点资讯和天天快报,哪一家会走得更远?