

近期,挚金资本联合狗尾草智能科技,承办了“人工智能 x 知识图谱”专项论坛。在本文中,深圳狗尾草智能科技公司CTO王昊奋对国内外聊天机器人的发展及背后的技术进行了梳理,也给出了自己对于未来聊天机器人发展趋势的理解。以下是演讲全文:
今天我们不是要讲宽泛的机器人,而是聚焦到更具体的聊天机器人。聊天机器人有些是偏软件的,也有些是软硬结合的。在这里,我们梳理一下聊天机器人技术的发展以及我们的思考。基于这些思考,我们又是如何应用在产品中,并怎样发现一些新的挑战和应对时的一些心得。

1、业界几种不同聊天机器人技术比较
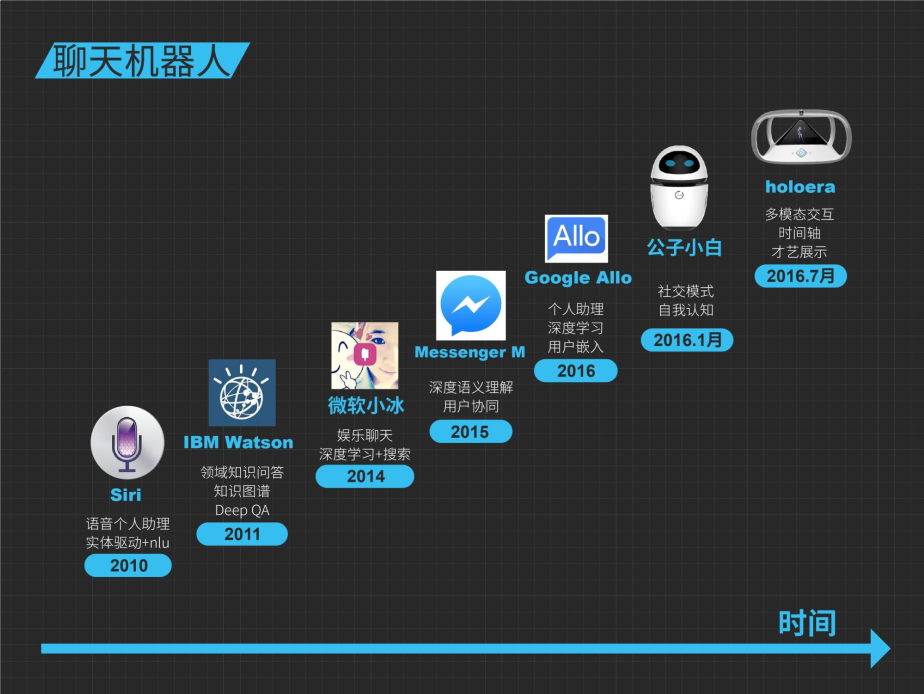
这是在时间轴上铺开列出我们想要介绍的聊天机器人,除了最上面两款公子小白和holoera之外,我并没有介绍其它国内的,因为披露的资料很少,为了避免片面性,所以这里列出了都是国外的聊天机器人,因为公开的资料相对比较丰富。
2010年苹果在iPhone 4S上推出了SIRI,现在看来SIRI很多时候成为我们戏弄的小玩具,但当时出来的时候大家对它的期望很高,并且它承载着一个想法就是个人助理;
2011年的时候IBM推出了Watson,在Jeopardy!(危险边缘,一个类似于国内的一站到底或开心辞典问答比赛)中战胜了常胜冠军,当时也比较轰动;
2014年微软推出了小冰,大家应该都玩过小冰吧;之后大家发现出现了越来越多的聊天机器人或者聊天机器人平台,在之前的Facebook F8的开发大会上,Facebook提出了新的Messenger M平台,谷歌在开发者大会上提出了全新的语音助手Allo,会承载新一代的个人助理。
我们在今年年初推出了公子小白,而7月8号发布会则揭开了全新AI+VR+游戏+IP的holoera。

SIRI处理过程中是实体驱动或本体驱动的NLU,而NLU称为自然语言理解,也属于自然语言处理的范畴。其实SIRI能做什么大家都清楚,例如可以帮我订餐,也能帮我做日程的管理,也能帮我播放本地的音乐。当然SIRI也有很多问题解决不了,此时会调用搜索引擎来兜底。
虽然我之前也调侃过SIRI,不过最近很多人反映说SIRI变聪明了。为什么会变得更聪明呢?因为SIRI从大家的交互中进行了总结,并通过学习算法优化了其智能。另一方面,最近SIRI的核心人员又独立做了一个进阶版的SIRI叫Viv,它的作用更加明确,就是拒绝去做闲聊,而充当一个真正的个人助理。
那么个人助理到底做什么呢?其实就是帮我解决各种各样的问题。当然大家可以理解类似于是一个超级APP的概念,其实是集成了各种各样的应用包括各种各样的服务,类似于早期Web服务里面的Web服务的整合和执行的调度。
比如说我可能订餐,我需要了解到用户的偏好,以及吃饭的对象、人员数量以及是你本身所在的位置和吃饭的时间等,以及可能像这里面集成类似大众点评这样的点评,来综合考虑这样的信息。Viv在个基础上实现了不需要下载第三方APP,通过Restful协议来调用这些应用。
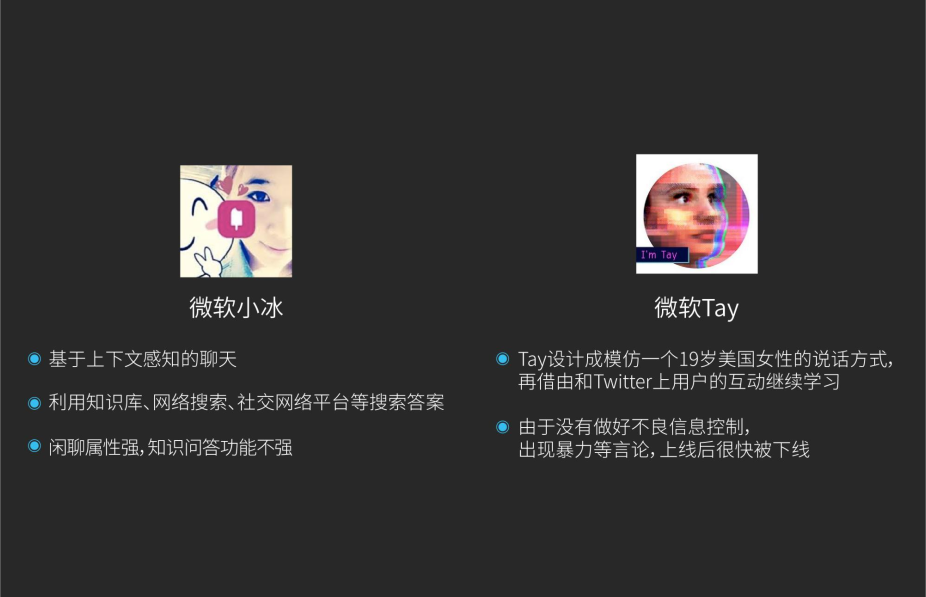
小冰跟刚刚的Viv正好相反,它就是希望你去闲聊,是面向口语化的一些对话,这里面其实是支持上下文,它需要支持的并非是单轮对话,而是多人对话,也是利用到了知识库、网络搜索和社交网络平台来搜索答案。与传统的搜索相比,你并不是得到一些网页的信息,而是在搜索结果基础上通过整合和后处理得到更精确的回答。
总的来说它的闲聊水平比较强,但是它的知识问答功能会比较弱化一点。当然小冰也在刻意追求这样一个事情,会不断上线一些新的功能让大家尝试。
与之对应的,微软本部做了一个Tay系统,没有像小冰这么著名,但是大家也都知道,Tay是模仿19岁美国女性的,它在Twitter上面跟大家交互,很多网民把它教坏了,所以有一些色情暴力包括种族歧视,上线没多久就被迫下架,我们也从这里面吸取经验教训。
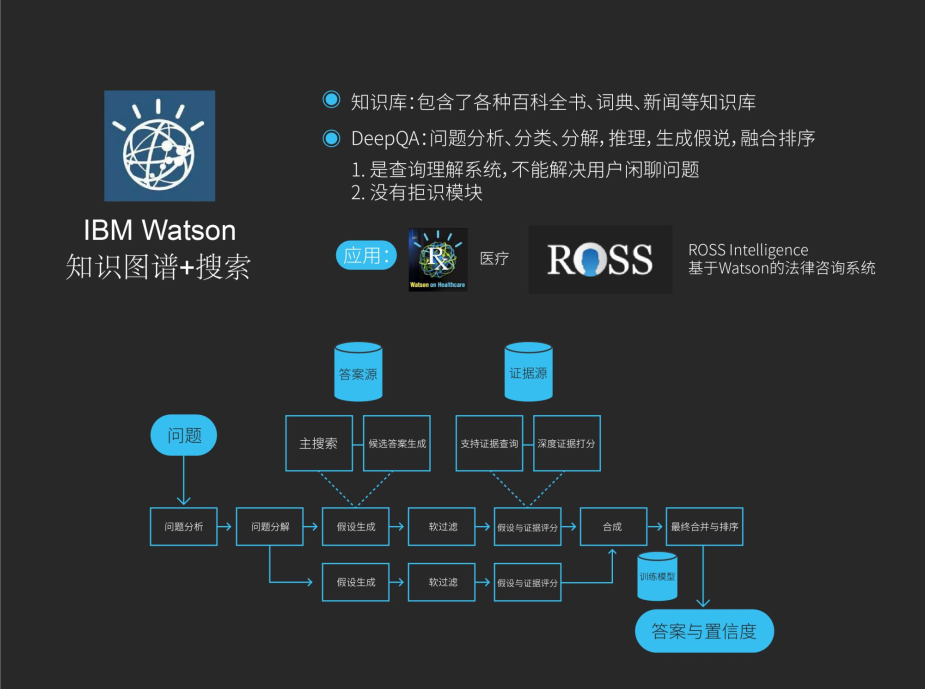
再就是IBM的Watson,上图是它的基本框架,有问题的分析、分解,有假设生成,基于各种证据对假设进行不同方面的评分,最后综合这些评分,来决定到底选取哪一个答案作为正确答案。本质来说Watson是一个问答系统,并不支持闲聊,因为它也不需要包含闲聊。
第二,它其实没有一个称之为拒识,就是拒绝识别,对于人工智能来说很重要的是你不仅需要知道你会什么,更重要的是你不会什么,不会什么比会什么更开放,当你不清楚你会什么的时候,很多时候你就会乱回答,胡乱回答用户体验就会不好,拒识是很重要的。
IBM的Watson相比于AlphaGo或之前下象棋的深蓝,它本身的商业价值更大,因此之后形成了Watson事业部,配合IBM的智慧地球及最近认知方面的策略。目前它做了两块应用,一块在医疗,用于癌症的辅助诊断;另一块,基于Watson技术出了一个Ross的机器人,是作为律师的辅助。

之后是Facebook的Messenger M,它2014年收购了Wit.ai,这家公司是传统做聊天的公司,它看中了这家公司在聊天对话场景和聊天策略方面的经验,与此同时,Facebook也有研究院,他们近期推出了DeepText的框架,基于深度学习不断地学习到聊天内容中包括主题在内的语义知识。前者作为冷启动,而后者则基于大数据更好的学习深层语义信息。
这里我想要强调的是任何全自动的方法,如果你要保证很强的精准度的话,现在是没有办法做到的。所以Facebook雇佣了很多人,谷歌也如此,其实有很多是基于机器反馈的答案做后纠正,这些后纠正是类似于像客服人员做审核。这些校对和纠正能帮助机器更好的了解什么时候更容易犯错,通过增强学习来调整策略和回答模型使得后面的回答更倾向于避免这样的错误。

之后还有谷歌新一代语音助手Allo,之前谷歌做了一个自动回复邮件的系统,和做Allo的是一批人,Allo对我们有意义的地方在于考虑到用户的偏好和用户的画像,特别是在问题的分类、场景的分析以及在回答的一致性方面。
其实这里面有很多问题,很多时候聊天机器人在多轮回答的时候一致性是不能得到保证的。此外,不同的人希望得到不同的回答,特别是当我了解它更深的时候希望得到的信息更加个性化。
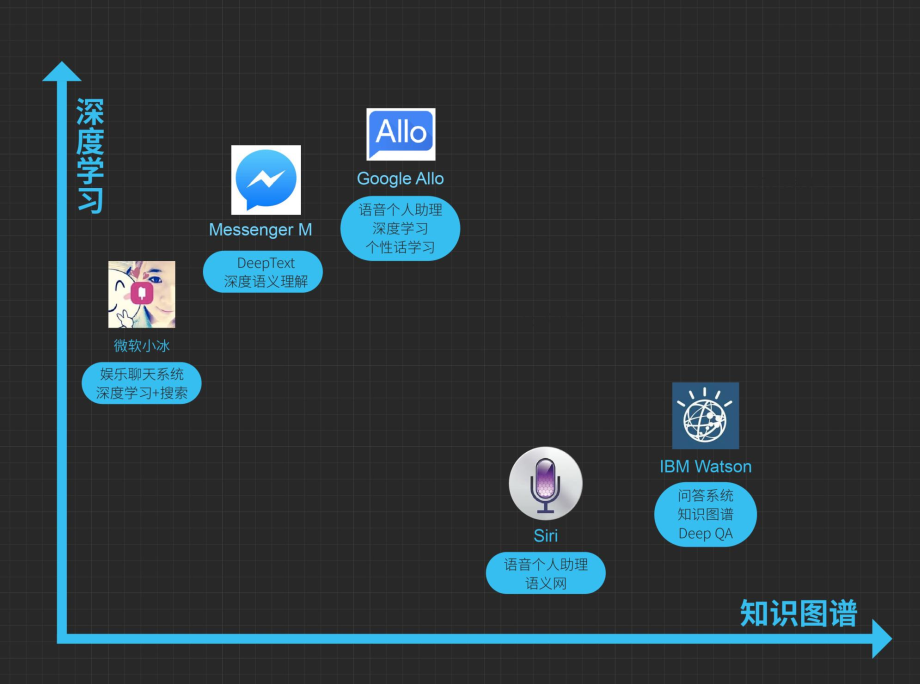
我们又根据深度学习和知识图谱两个维度来组织上述聊天机器人,SIRI和Watson在知识图谱上的探索更多,而小冰和MessengerM等在深度学习上探索的更多,相对来说Allo最为平衡。
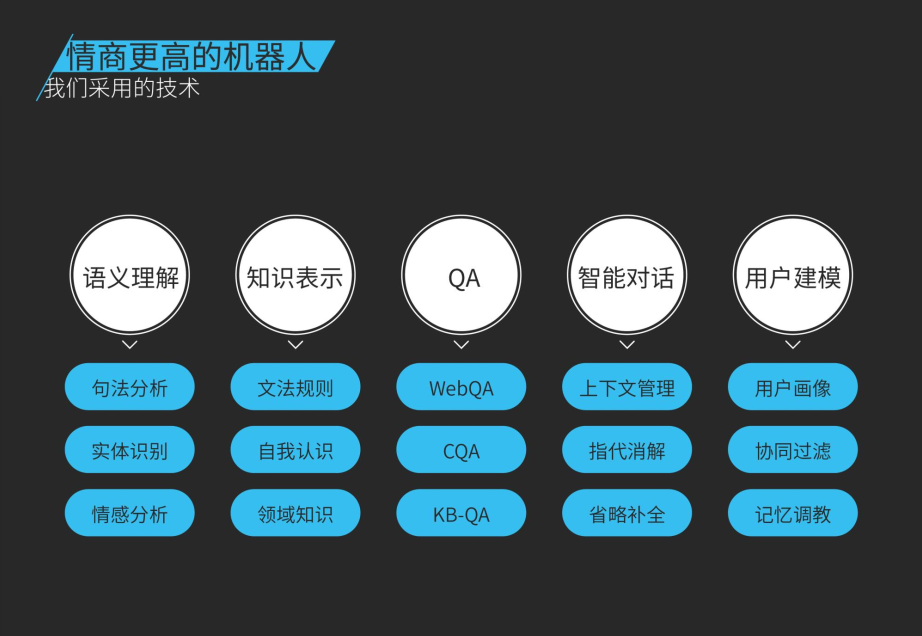
我们采用的技术比如语义理解,不仅包括词级别,还有句话级别、篇章段落级别,包括实体识别、句法分析、关系抽取,也会考虑情感计算。知识表示包括文法规则,还有自我认知,包括机器人的价值观和各种属性的设定等。QA技术包括在基于Web的问答,基于社交网站的社区问答CQA,以及基于知识库的KB-QA,还有智能对话这个方面。
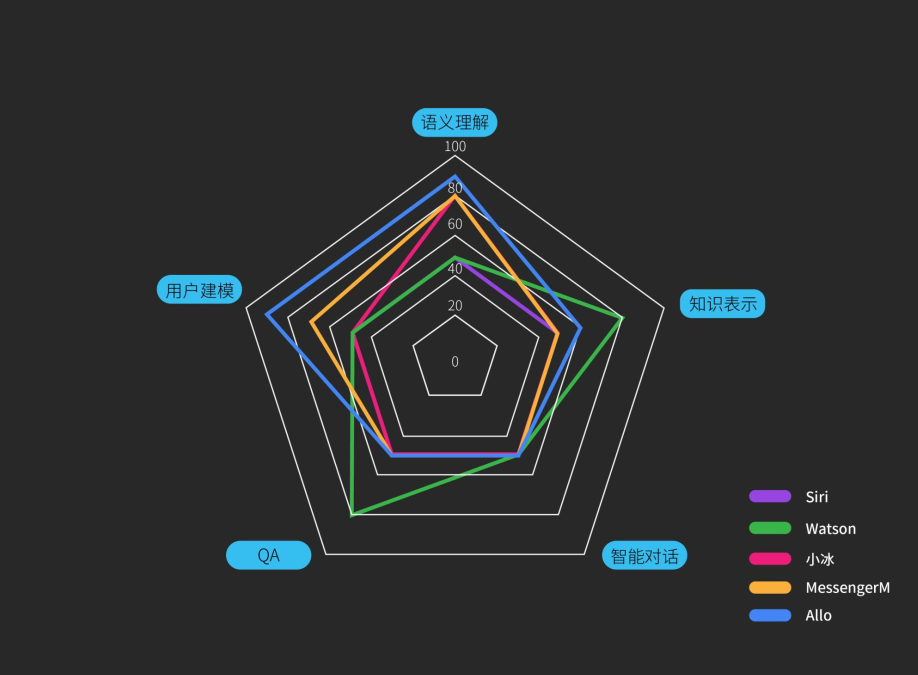
基于这几个纬度对系统重新进行打分,形成雷达图,可以很清晰看到Allo在语义理解、用户建模是比较高的,Watson在QA和知识表示方面是相对比较突出。
2、聊天机器人新的技术挑战

在这种情况下我们发现新的挑战,这些挑战有一些是单纯技术的,而有一些是我们称之为更有幸福感的技术;单纯的技术包括语音识别、人脸识别等属于感知智能范畴的,更有幸福感的技术则包括情感分析、用户建模,这些从聊天机器人的用户体验感的提升来说很重要,也包括记忆推理。

具体来说,我们希望用户和机器人之间建立强关联,虽然大家都玩过小冰,但是对用户的强社交性的支持并不是很好,我们希望建立用户和机器人的亲密感。
二是多模态的输入和输出,还有记忆和推理,既然给用户更好的建模,同时希望用户形成更好的认知系统,跟用户交流什么东西、他跟你说了什么东西,你应该有一定的辨别和判断,并且有一定的归纳和整理。
第三,说到某些话题的时候可能有些触类旁通或者有一些关联的事情,这称之为记忆和联想。
3、情商更高的机器人

单纯靠深度学习是不够的,知识图谱本身是知识的组织,两者是互补的。知识图谱为深度学习的训练提供先验知识,而基于知识图谱设计的用户画像和个性设定,则能保证虚拟人物交互信息的一致性。
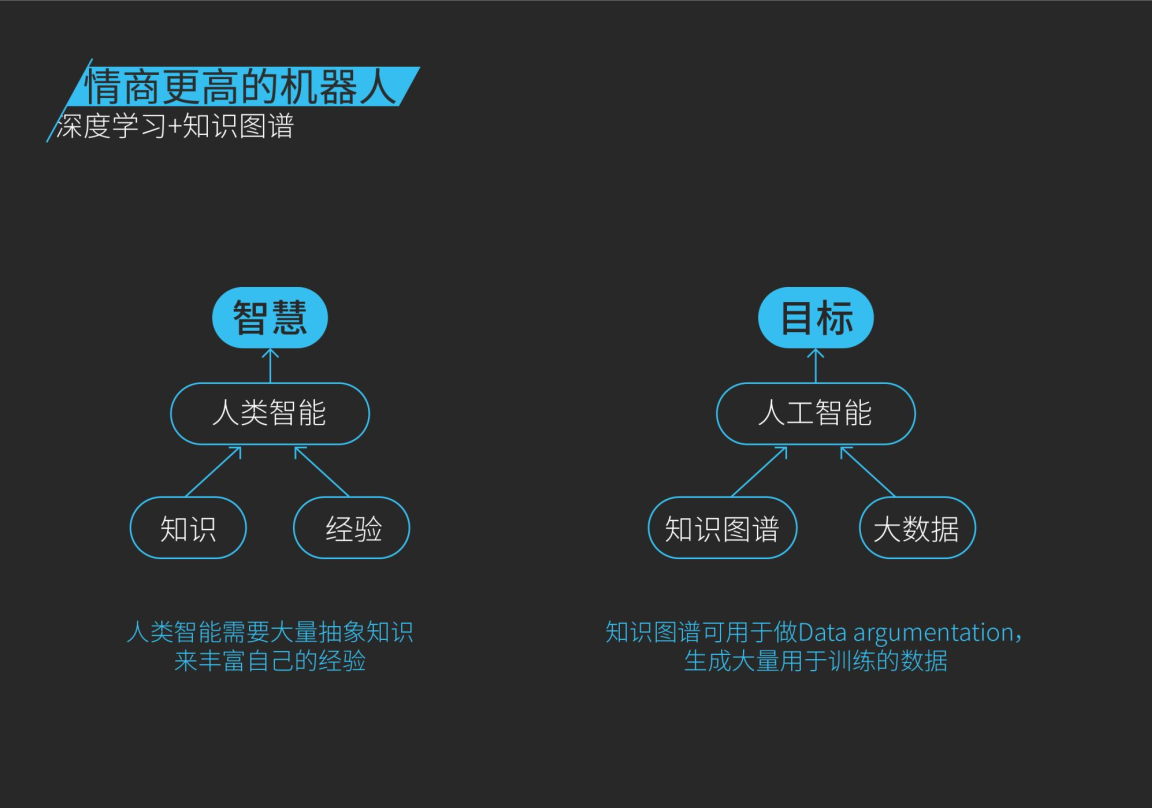
类比人类智慧的形成依赖知识和经验,机器依靠知识图谱和大数据,通过人工智能来类比人类。这里抽象知识积累所形成的经验可以通过知识规则或深度学习的模型来刻画,而深度学习训练需要的大数据可通过知识图谱的数据增强来实现。
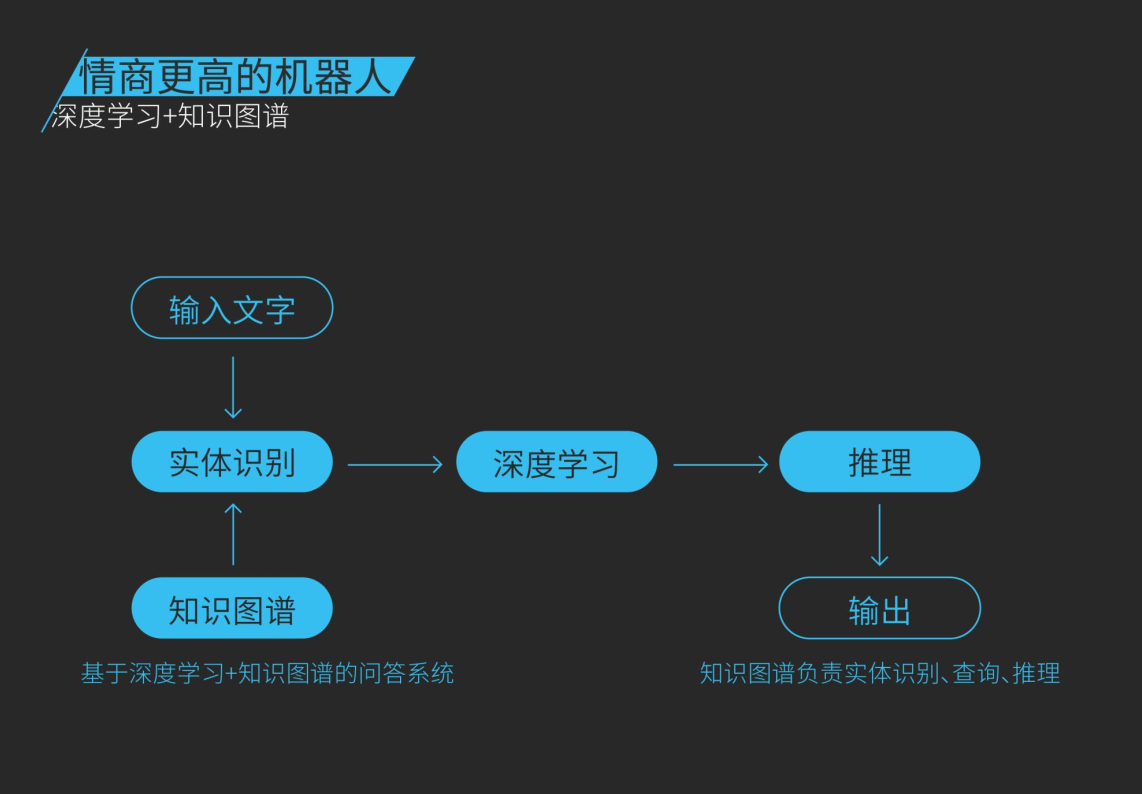
具体来说,一个通用的结合了知识图谱和深度学习的框架,依赖知识图谱对输入的文字进行实体和关系等语义理解,通过深度学习包括各种序列到序列学习的框架得到候选输出,通过推理来做最后回答的排序和过滤来实现最后的输出。
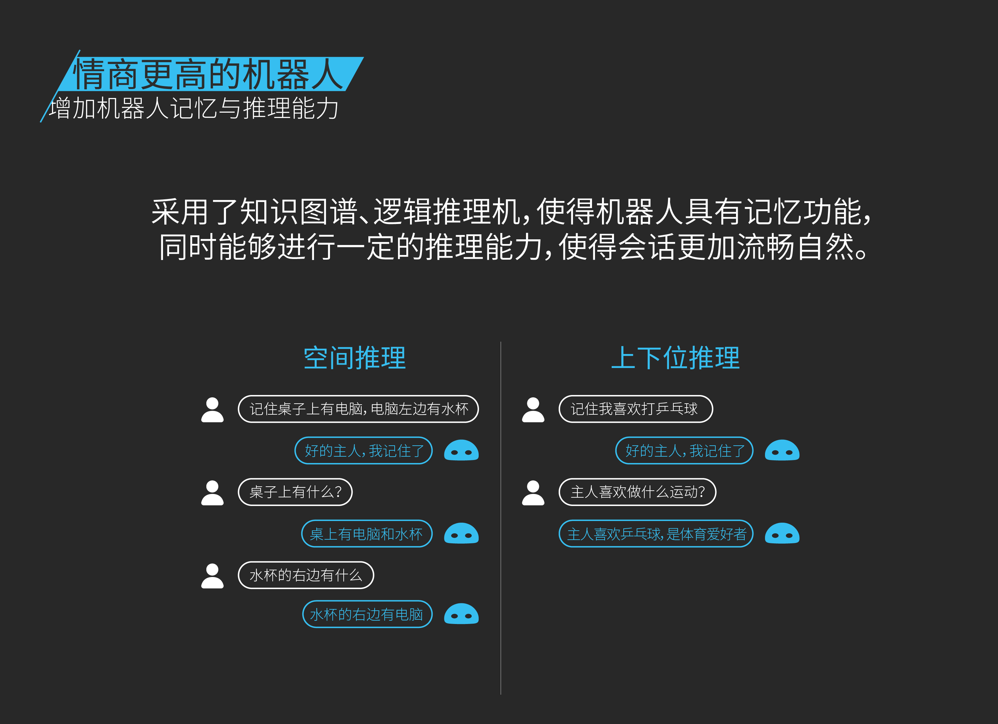
这里想强调一下推理的作用,采用了知识图谱特别是逻辑推理可以使得机器人具有记忆能力,同时使得会话更加自然流畅。下面展示了两种常用推理:
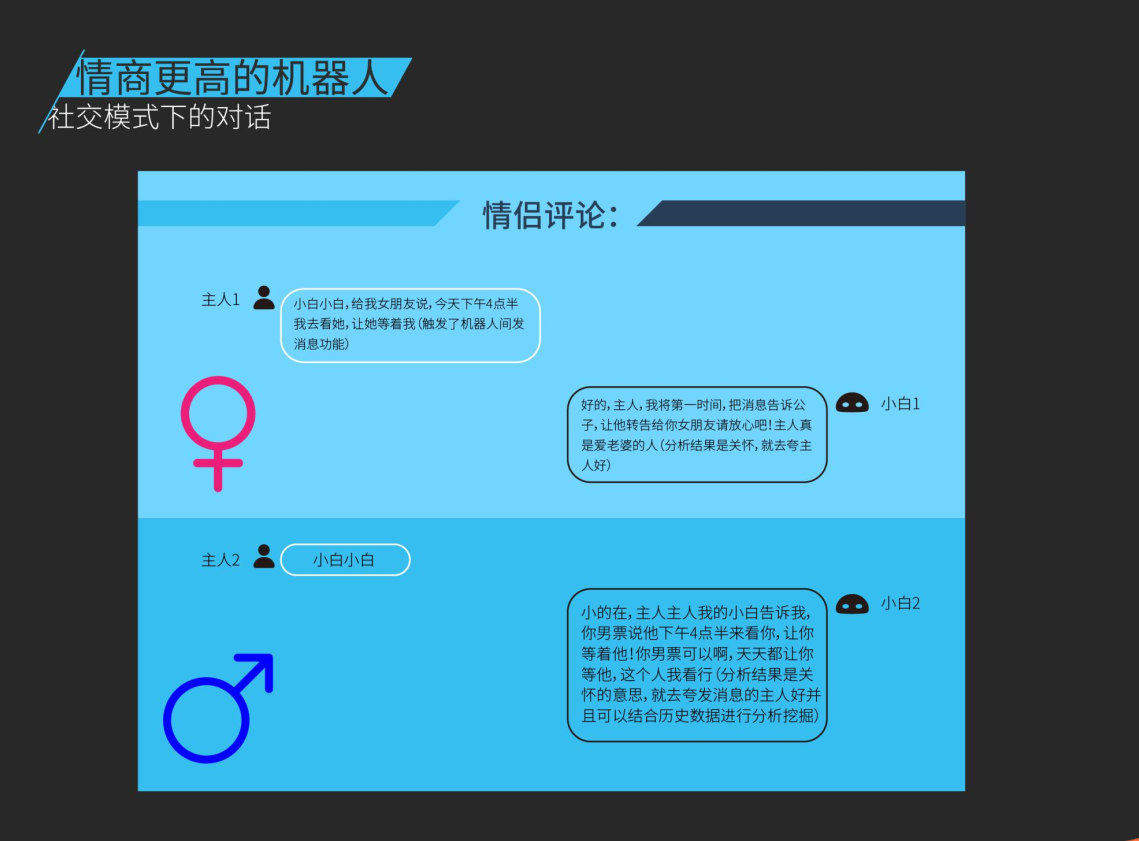
下面我们又展现了在社交模式特别是情侣模式下,如何通过场景推理结合情感评论非常有趣的交互:

4、AI+新一代的人工智能

上面是人工智能全新跨界的尝试holoera(全球首款人工智能3D投射虚拟增强游戏主机),生活在里面的首个羽泉签约的(虚拟)艺人琥珀。
挚金资本注:holoera是全球第一台人工智能全息3D主机,由Gowild赋予了人工智能的来自异次元的魔法美少女“琥珀·虚颜”居住其中。你可以近距离、全方位观看二次元明显“琥珀·虚颜”的日常,360度感受这款横跨娱乐、文学、游戏三界的超级IP所带来的新奇体验。

为了实现这个产品,我们额外需要做的是基于视觉信息的用户身份识别,第二是做不良交互内容的检测与识别,第三是时间轴生活场景,大家希望欣赏这样一个美少女在生活的24小时内所做的方方面面,她可能在睡觉、可能在表演等等,我们对于知识图谱进行动态时间轴上的扩展。同时建立用户亲密度和友好度,最后我们为了更好的提高语音识别的画像,我们还做了口形识别,动作合成这一块跟多模态输出是有关系的。
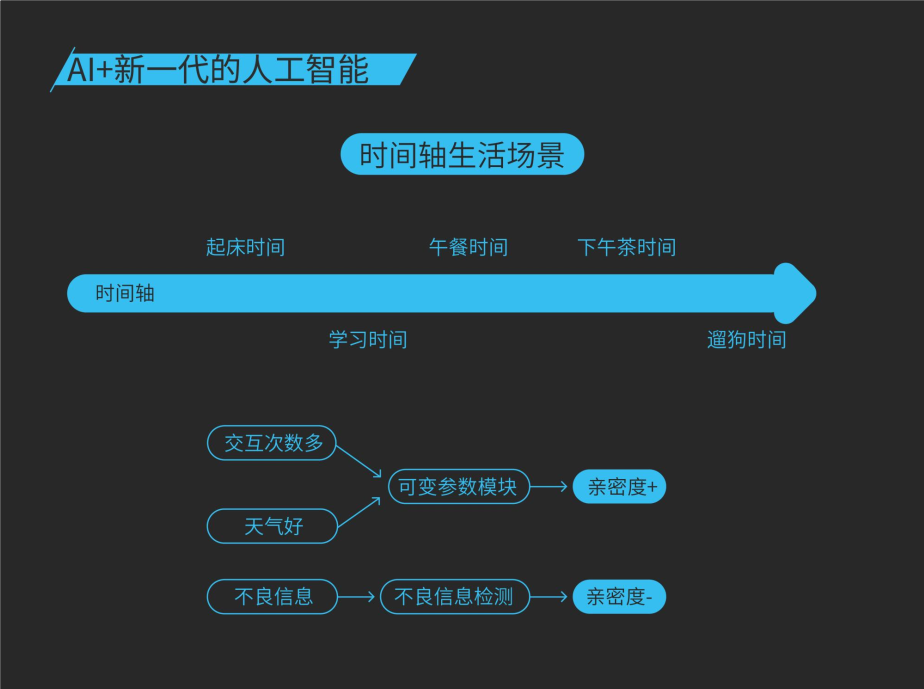
大家每天24小时先起床,有学习、午餐、下午茶等等,通过不同的交互和不同时间点发生的事件,特别是今天大家觉得很热,可能今天下午大家心情不好,航班延误了你心情不好,可能你吃了一个很好吃的冰激凌就会心情很好,我们会自适应的调整琥珀的参数。

人的交流不仅仅局限于语音与文字,表情、语气等多模态输出是必要。还会有表情、指纹、光感、语气和动作。


多模态输出,包括语气也会有表情、动作,对于琥珀来说动作交互更丰富一点。它的身份是虚拟艺人,它是签约在羽泉的艺人公司下面的,会发布自己的唱片,也会跟大家进行交互,说穿了它就是具有人工智能的初音。
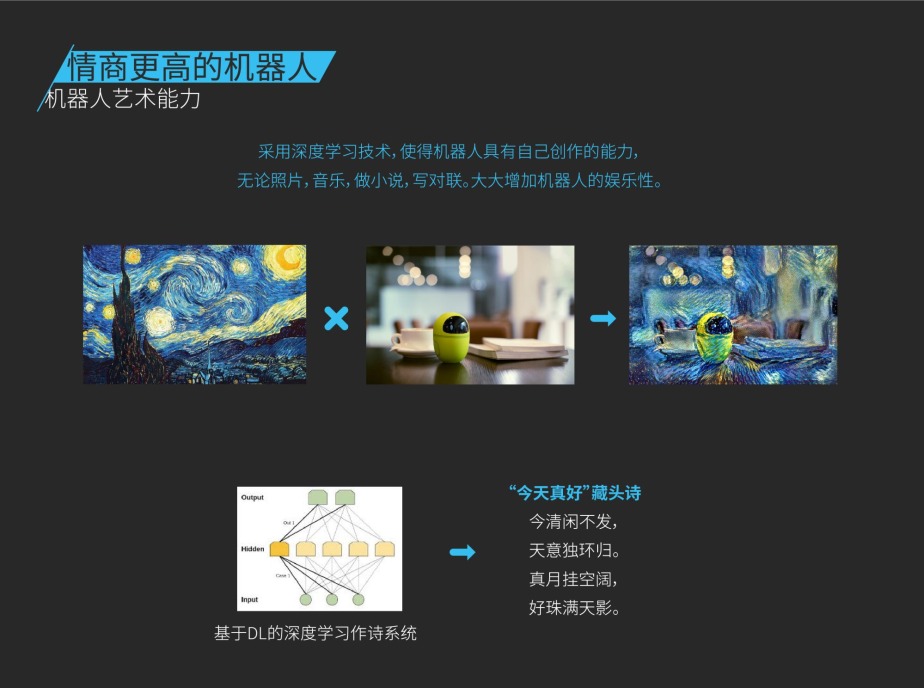
机器人需要更多的才艺,这里面我们更多的整合了很多深度学习的技术,比如说这是梵高的星空,当然也可以画素描,下面可以做诗,也可以做微小说,还有一些作曲。

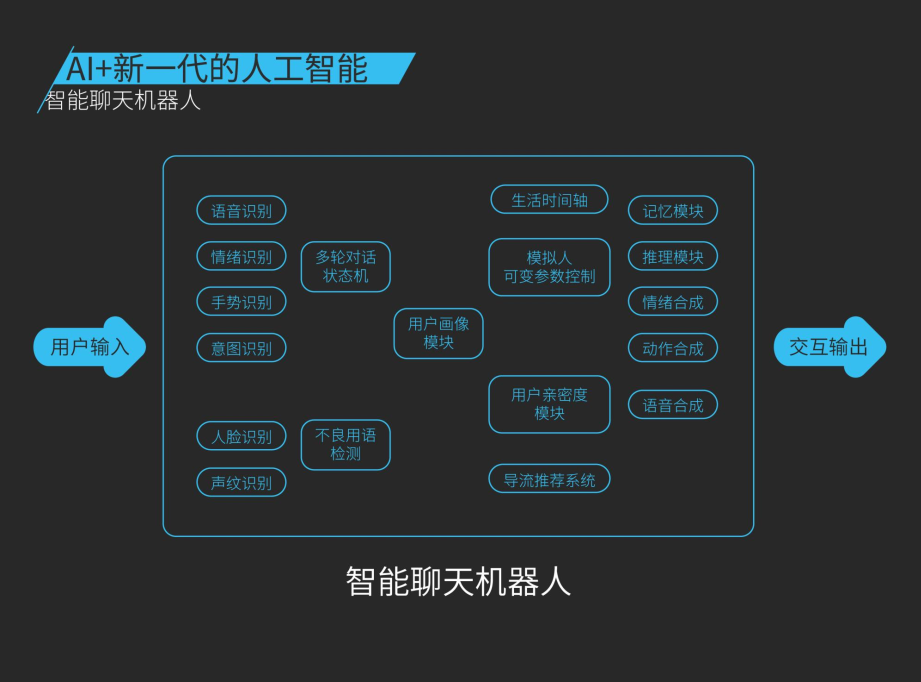
智能聊天系统对输入和输出当中的黑盒来说,其实应该包括各种各样的识别,包括语音识别、情绪识别、手势识别、人脸识别、身份识别,也包括各种各样的对话管理、用户画像管理,特别是对于美少女来说更需要去做这样一些对话内容的检测,还有生活的时间轴、用户管理和记忆推理、情绪合成、动作合成、语音合成等等一系列很复杂的工程加上技术实现。
作者:王昊奋,深圳狗尾草智能科技公司CTO,作为技术负责人,他带领团队构建的语义搜索系统在十亿三元组挑战赛(Billion Triple Challenge)中获得全球第2名;在著名的本体匹配竞赛OAEI的实体匹配任务中获得全球第1名。他带领团队构建了第一份中文语义互联知识库zhishi.me。
本文分享自挚金资本官方订阅号(ID:zhijincapital)。挚金资本是智金汇旗下的一家新锐投资机构,专注于机器人、人工智能领域。