

仅仅通过一个指标,例如 h 指数,来衡量科学家的学术影响力,这未免是对现实复杂性的过度简化。近日发表在 PNAS 上的新论文“科研影响力的三个维度”,通过中观维度(Meso level)的模型,利用三个指标,分别表示学者的总产出、总影响力以及该学者的幸运程度。该模型为科学学(Science of Science)又增添了新的工具。
本文来自微信公众号:集智俱乐部(ID:swarma_org),作者:郭瑞东,原标题为《“著名科学家”的门槛是什么?高产、高被引、好运气一个都不能少》,题图来自:IC photo

论文题目:Three dimensions of scientific impact
论文地址:https://www.pnas.org/content/early/2020/06/05/2001064117
一、如何评价学术影响力
现在有一对双胞胎分别跟着不同的导师读博士,哥哥跟着学界权威,毕业时已经发了多篇论文,各篇引用都不少;而弟弟跟着新晋导师,毕业时只完成了一篇论文,但这篇论文却有极大潜力。那我们该如何评价兄弟两人的学术影响力?
如果按照 h 指数来看,即某个人发表了有 h 篇论文,每一篇至少被引用了至少 h 次来看,那么哥哥的成就更大。然而这样的评价方式,首先没有考虑到运气的影响,其次,忽略了富者越富的马太效应。
在学术界中,一项具有奠基性的研究,会被之后所有的相关研究引用,从而使得这样的文章获得大量引用。例如巴拉巴西提出 BA 模型的论文,就是网络科学中被引用最多的论文之一。这就是在学界被广泛证实的现象,称之为“由过往成功带来的成功”。
如何在对科研影响力进行评价时,同时考虑到运气和偏好依附(Preferential attachment)的影响,是本文要解决的问题,也是其创新点所在。其文中所提及的用三个指标来评价某领域学者的科研影响力,则是该模型的副产品。
二、中观视角,描述复杂问题的新方法
传统上的建模,要么是宏观的,从统计指标出发,去找到不同指标间的相关性;要么是微观的,先假设产生该现象的机制,再看什么样的参数能够再现出现实情况。
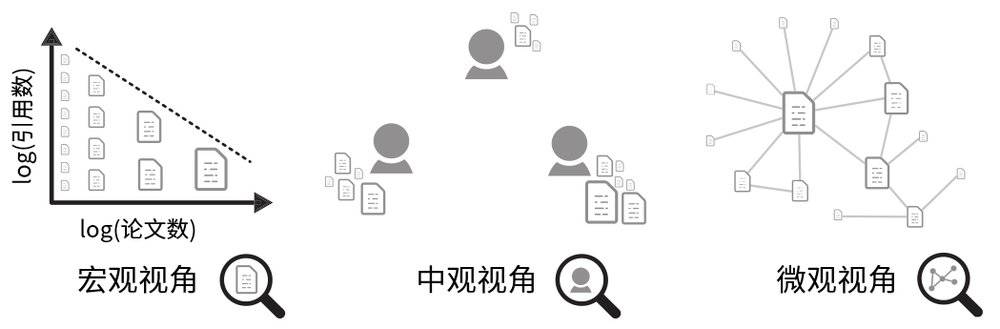
图1:宏观、中观、微观视角对比
在对学者影响力的建模上,宏观视角是用来找到在不同学科中,论文发表数量和被引用数之间的统计规律;而微观视角下研究主体变得很小,通过巴拉巴西提出的优先连接的机制,或基于主体的模型,其关注的是每篇论文的发表时间及影响力符合何种规律,而没有触及学者的影响力这一方面。
宏观模型描述的是整个学科的规律,微观模型描述的是单篇论文的引用量具有的特征。而中观视角,则介于宏观与微观之间,其研究对象的粒度,是以学者为单位的。而研究方法,则是基于对现象成因的理解,自下而上地用几个参数,来重新发现生活中的数据所具有的特征。
宏观视角下,每篇论文的引用数,经排序之后,会发现其符合指数分布;但这个规律,并不适合单个科学家。采用中观视角后,可以将每个研究者的 N 篇论文,及其各自的引用数,用更少的指标进行描述,并对每个指标给出清晰的解释,这体现了中观视角的优势。
在其它类似的问题上,例如对风险投资及其成功率的建模,也可以采用中观视角。关注各个投资机构,而不是整个行业(宏观)或者每一笔投资(微观)是否成功,其受到哪些因素的影响?这是该文带给读者方法论层面的启发。
三、模型中的三个组成项及其意义
不同于科学学研究中常用的 APA 数据集,该文的数据来自计算机科学,称为 DBLP。其包含 176 万名研究者,309 万篇论文和 2516 万次引用关系,该数据库还在持续更新中。
在 2020 年最新版的 DBLP 数据库中,已包含 489 万论文和 4556 万次引用关系。其中包含了文章标题,摘要,年份,影响因子等诸多信息,是一份值得深挖的数据集。
数据库中大量引用数过少的论文,会造成模型对长尾效应的过拟合。为避免上述影响,该文关注的只是 h 指数大于 5 的研究者及其发表的论文,以及这些研究者之间的引用网络。
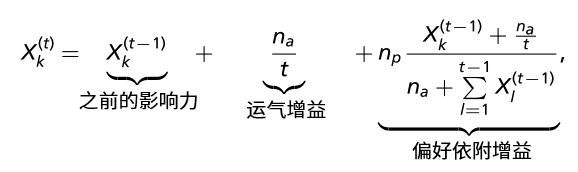
在建模过程中,将每名研究者的影响力,设定为 X,每发表一篇论文,就会增加X所代表的值。其中一部分来自该论文因为运气所获得的引用,一部分源于该论文由于之前的成功所获得的引用,由此,可以得到下面的公式:
而从宏观的角度来看,按照上述的规则模拟,平均来看,给定每个人的总论文数为 N,被引用数合计为 C 以及论文引用中有多少为来自随机性的影响(用 ρ 描述,ρ 为 0 代表引用完全由于随机影响,ρ 为 1 代表该论文的引用完全来自之前的成功)可以推出平均每个研究者预期的 X 值,为下式:
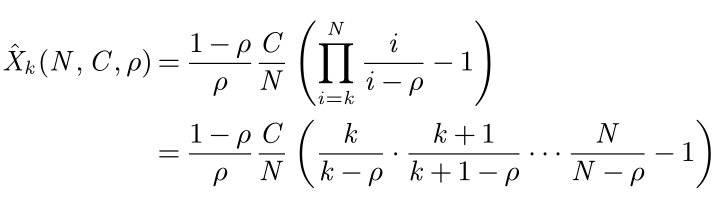
N 和 C 的值,能够从原数据中经简单的统计获得。通过将所有研究者的 Xk 与X^k(N,C,ρ)的差进行整合,可以找到使两者之差最小化的 ρ 值,由此可以使用这三个指标,来描述某个学科论文发表中所呈现的规律。
四、越成功的研究者,其受随机性的影响越低
按照发表总论文数,将研究者分为 4 档,分别观察各档科学家所对应的 ρ 值,可以得到下图:
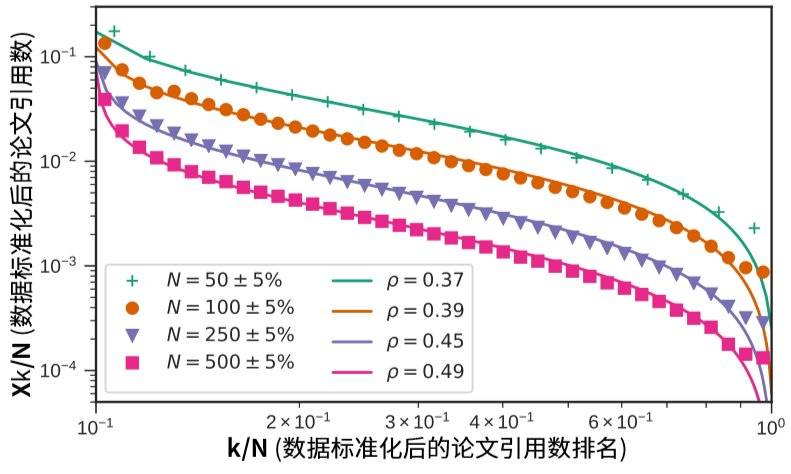
图2:总发文数不同的作者,其引用数呈现不同的规律
图中不同颜色的图形,代表不同档位的研究者,例如绿色代表总论文数在 48~52 篇之间的 2624 名研究者,橙色代表在 95~105 篇之间的 1113 名研究者。图中的每个点代表一篇论文。横轴是论文引用数的排名,纵轴是引用数。
该图指出:越高产的研究者,其论文的引用数就越不平均,对应于该档研究者中拟合的 ρ 值的平均就越大,这说明学术界存在着富者越富的情况。
由于总论文数更多的作者,有更大的可能是资深研究者,而他们发表的文章引用数却有很大差异,这意味着对于那些已经发表过爆款论文的研究者,有很大可能其最有影响力的研究已经发表。而这与之前对科研论文引用网络进行的研究所指出的“成功可能发生在职业生涯的任何一个阶段”可以相互印证。

图3:总产出,总引用数和 ρ 值的关系
上图进一步,将模型中的三个参数的关系展现了出来。其中不同颜色的线代表了,该类作者中,超过 25%,50% 及 75% 的其他研究者的所对应 ρ 值,左图横轴为总论文数,右图为总引用数。
有 30% 的研究者,其 ρ 值为 0,这些研究者大多处于学术生涯的早期,或者其最具影响力的文章还没有出现,从上图的左下角可以看出。
使用该指标,能够更好地评价青年研究者的学术潜力。比如两个 N 和 C 值相同的研究者,ρ 值越高,说明其研究越多地是占坑型的(基于以前研究的扩展型),而不是原创型的。
回到本文开篇的问题,该如何评价一对跟了不同类型导师的双胞胎博士毕业时的学术成就?用单一的指标,总会丢掉一些信息,唯有通过多个指标,才能描绘现实中的复杂性。
五、未来的研究方向展望
关于这篇论文本身的介绍,就到这里。在研究了该文的数据集后,笔者认为,基于该数据及本文提出的模型,还可以回答如下问题:
首先是不同年份的论文,其对应的平均 ρ 值是怎样变化的?是否有一致的趋势?如果 ρ 值越来越大,说明计算机领域真正开创性的研究越来越稀少。类似地,基于关键词可以得出在不同领域,例如计算机视觉,语音识别等对应的平均 ρ 值,并以此判断该领域的原创程度。
其次可以看到,处于不同阶段的平均 ρ 值不同的研究者,其科研合作呈现怎样的特征?是不是越是资深研究者的论文,就越有可能是来自大团队,由多名作者合作完成?而那些青年研究者,是否更有可能在小团队中,能够获得更好的训练,从而在未来更加成功?
最后,在微观的层面看,论文的题目和文章的原创性有没有关系?例如是不是题目越短的论文,其原创性越强?还可以根据题目中 review、survey 等关键词找出综述类文章。并比较综述类文章的引用量,是否总是显著地高于该学者论文的平均引用量?这些问题,也可以基于该文的数据进行研究。
本文来自微信公众号:集智俱乐部(ID:swarma_org),作者:郭瑞东